二項分布の検定と推定 1

公開日2020年5月25日 最終更新日 2021年9月20日
みなさんこんにちは、michiです。
前回までは「連続量」に対して検定と推定の勉強をしました。
※前回の記事では「分散の推定」について学びました。
\[\]
しかし、検定や推定をしたいデータが離散的な場合もあります。
例えば、不良発生数や朝寝坊の回数などです。
このような離散的な場合について、二項分布を使った検定と推定をやってみましょう。
キーワード:「期待値」「分散」「確率」
\[\]
目次
①二項分布の復習
二項分布が何だったのか忘れている人もいるかもしれないので、簡単に復習してみましょう。
二項分布は以下の式で表される分布でした。
\[\small{n}C\small{x}×p^x×(1-p)^{n-x}\]
\(n\):全体数、\(x\):注目する事象の発生数、\(p\):注目する事象の発生確率
この時の期待値\(E(\bar{x})\)と、分散\(V(x)\)は、
\[E(\bar{x})=np, \qquad V(x)=np(1-p)\]
でした。詳細は記事「二項分布の考え方」「二項分布期待値の導出」をご参考ください。
二項分布は期待値 \(np\) ≧ 5 の時は、正規分布に近似して考えることができます。
そのため、離散的な値の分散を表す二項分布でも、正規分布をベースに検定と推定が可能になるのです。

\[\]
②二項分布の検定統計量の求め方
二項分布の検定統計量を考えるために、ベースとなる正規分布の検定統計量\(Z\)を考えます。
\[Z\qquad=\frac{\bar{x}-μ}{\frac{σ}{\sqrt{n}}}\qquad=\frac{標本平均-母平均}{\frac{母標準偏差}{\sqrt{サンプル数}}}\]
正規分布の検定統計量\(Z\)を二項分布に当てはめると、「標本平均」は「抽出したサンプルの中で注目する事象の発生する回数」と考えられます。
これは、二項分布でいう「期待値」のことですから、\(\bar{x}\) ⇒ \(np\)となります。
※発生回数=サンプル数\(n\)×発生確率\(p\)
\[\]
次に正規分布における「母平均」を二項分布で考えると、「注目する事象の発生する回数」です。
(。´・ω・)?
二項分布の期待値と何が違うのかわかりにくいですね。
標本平均に当たる二項分布の期待値は、抽出したサンプルから得られる値。
母平均に当たるものは、サンプル数に関係のない「真の値」といったところです。
この「真の値」が発生する確率を\(P_0\)とすると、
母平均 \(μ\) ⇒ \(nP_0\) となります。

\[\]
最後に母標準偏差\(σ\)ですが、これに相当するのは\(\sqrt{母分散}\)ですので、
\[σ ⇒ \sqrt{nP_0(1-P_0)}\]
と変換できます。よって、二項分布の統計量は
\[Z\qquad=\frac{\bar{x}-μ}{\frac{σ}{\sqrt{n}}}\qquad ⇒Z\qquad=\frac{np-nP_0}{\sqrt{\frac{nP_0(1-P_0)}{n}}}\]
\[=\frac{np-nP_0}{\sqrt{P_0(1-P_0)}}\]
\[\]
また、正規分布の検定統計量\(Z\)に合わせるために\(n\)で割ると
\[Z=\frac{p-P_0}{\sqrt{\frac{P_0(1-P_0)}{n}}}\]
こちらのほうが検定統計量として、一般的によくみます。この場合、
\(\bar{x}\)⇒\(p\)、\(μ\)⇒\(P_0\)、\(σ\)⇒\(\sqrt{P_0(1-P_0)}\) と変換していることになります。
注目する事象の発生回数に対する検定統計量が、発生確率に対する検定統計量へなりました。

\[\]
③推定方法
それでは、本題の二項分布の推定方法について解説していきます。
この時の推定は確率に対して推定をしていきます。
点推定は \(p=\frac{x}{n}\)
区間推定は、 \(p±Z(\frac{α}{2})×\sqrt{\frac{p(1-p)}{n}}\) となります。
まず点推定ですが、「注目する事象の発生回数」を「全試行回数」で割るわけですから、\(p\)は標本から得られた「注目する事象の発生する確率」を「真の確率」をみなしています。
区間推定については、正規分布の区間推定の範囲は、
\[\bar{x}±Z(\frac{α}{2})×\frac{σ}{\sqrt{n}}\]
見比べると、\(\bar{x}\) ⇒ 確率\(p\) と変換されているわけですが、
母標準偏差\(σ\) ⇒ 標本標準偏差\(\sqrt{p(1-p)}\) となっています。
(。´・ω・)? ナゼ?
正規分布に合わせるのであれば、\(σ\)⇒\(\sqrt{P_0(1-P_0)}\) のような気がしますよね・・・
\[\]
この考え方の理由は、推定は「抽出したサンプル」からするためです。
点推定では、求める確率を\(p=\frac{x}{n}\) としていました。
同様に求める区間推定も抽出したサンプルより得られた\(p\)を使うのです。

\[\]
④問題を解いてみる
いままで学んだことを復習するために、二項分布に対して「仮説の設定⇒検定⇒推定」とやってみましょう。
問)Aさんが寝坊する確率は\(P_0=0.05\)であった。しかし、最近よく夜更かしをするため、100日間で8回寝坊していた。Aさんの寝坊する確率に変化があったと言えるだろうか。第一種の誤りを5%として答えてね
\[\]
寝坊する回数は連続量ではなく離散的な値(1.23回寝坊したとかはない)なので、二項分布が使えそう。
\(np=100×0.08=8≧5\) なので、二項分布で検定・推定が可能
仮説の設定)今回の帰無仮説は「Aさんの寝坊する確率は今も昔も変わらない」。
対立仮説は「Aさんの寝坊する確率は今と昔で異なる」になります。
今回の問題は変化があったか否かを問われるので、両側検定となります。
検定)統計検定量\(Z\)は
\[Z=\frac{p-P_0}{\sqrt{\frac{P_0(1-P_0)}{n}}}\]
\(p=\frac{x}{n}=\frac{8}{100}=0.08,P_0=0.05\)を代入して、
\[Z=\frac{0.08-0.05}{\sqrt{\frac{0.05(1-0.05)}{100}}}\qquad=\frac{0.03}{\frac{0.2179}{10}}\qquad≒1.376\]
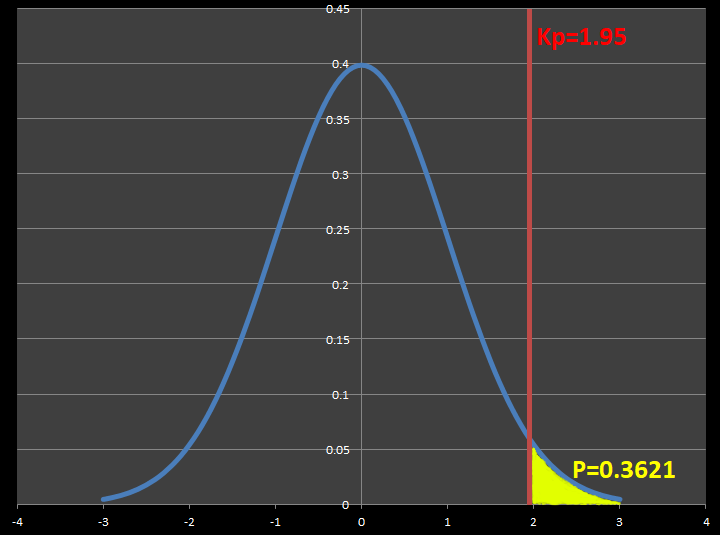
この検定統計量の値を正規分表の棄却限界値と比較すると・・・

検定統計量\(Z\)=1.376<棄却限界値=1.960 となります。
検定統計量\(Z\)は採択域内にあるため、帰無仮説が採択され、「Aさんの寝坊する確率は今も昔も変わったとは言えない」となります。
\[\]
推定)次に推定を行います。
点推定は\(\frac{8}{100}=0.08\)です。
次に信頼度95%で区間推定をすると
\[p±Z(\frac{α}{2})×\sqrt{\frac{p(1-p)}{n}}\]
\[=0.08±1.96×\sqrt{\frac{0.08×0.92}{100}}\]
\[≒0.08±0.058\]
よって信頼度95%の信頼区間は 0.022~0.138
\[\]
検定結果より、帰無仮説が採択されたのでAさんの寝坊する確率は変わっていないと判定しました。
しかし、ここ100日間の寝坊する確率は8%(点推定)であり、推定結果より寝坊する確率が3%~13%の間(区間推定)は、「現在の寝坊率8%」から変化はないと判断されます。
\[\]
100日で8回寝坊していた人が、半分の4回や1.5倍の12回寝坊しても、統計的には変化していないと判断されます。
今回は寝坊を例に考えましたが、例えば、通常の生産工程でも不良発生数が半分になっても分布を加味しないことには、減ったか変わらないか判断できないのです。

\[\]
まとめ
①二項分布は\(\small{n}C\small{x}×p^x×(1-p)^{n-x}\) で表される
②二項分布の検定統計量は正規分布のものをベースに決定
③推定では、サンプルから得られた確率\(p\)のみを使う
④何かの回数が半分になっても、分布によっては統計的には変化がない
\[\]
今回は二項分布の検定・推定を行いました。
次回は二つの成分からなる二項分布の検定・推定を勉強しましょう!














[…] まず点推定ですが、「二項分布の検定と推定 1」で紹介したように、ある一つの集団の点推定は、(p=frac{x}{n}) ((n):サンプル数、(x):発生回数) でした。 […]
[…] 具体的な例をあげると、記事「二項分布の検定と推定 1」では、Aさんの寝坊回数について検定と推定をしました。 […]
[…] 今回は少し短めの内容でしたが、次回は二項分布の検定・推定について学んでいきます。 […]
[…] 前回までは二項分布とポアソン分布の検定・推定を学びました。 […]